Challenge
The challenge was merging LoRA adapters into large SafeTensors models on a single workstation.
Case Study
A Rust-based tool for merging LoRA adapters into SafeTensors models with memory-mapped I/O and low-memory workflows for large models.
Developer Tools · AI Infrastructure · Model Tooling · LoRA Adapters
The challenge was merging LoRA adapters into large SafeTensors models on a single workstation.
SafeTensors Surgery memory-mapped the base model, processed one tensor at a time, applied the LoRA adapter changes with high-precision math, and wrote a merged SafeTensors model artifact that preserved the original layout, dtype, and metadata.
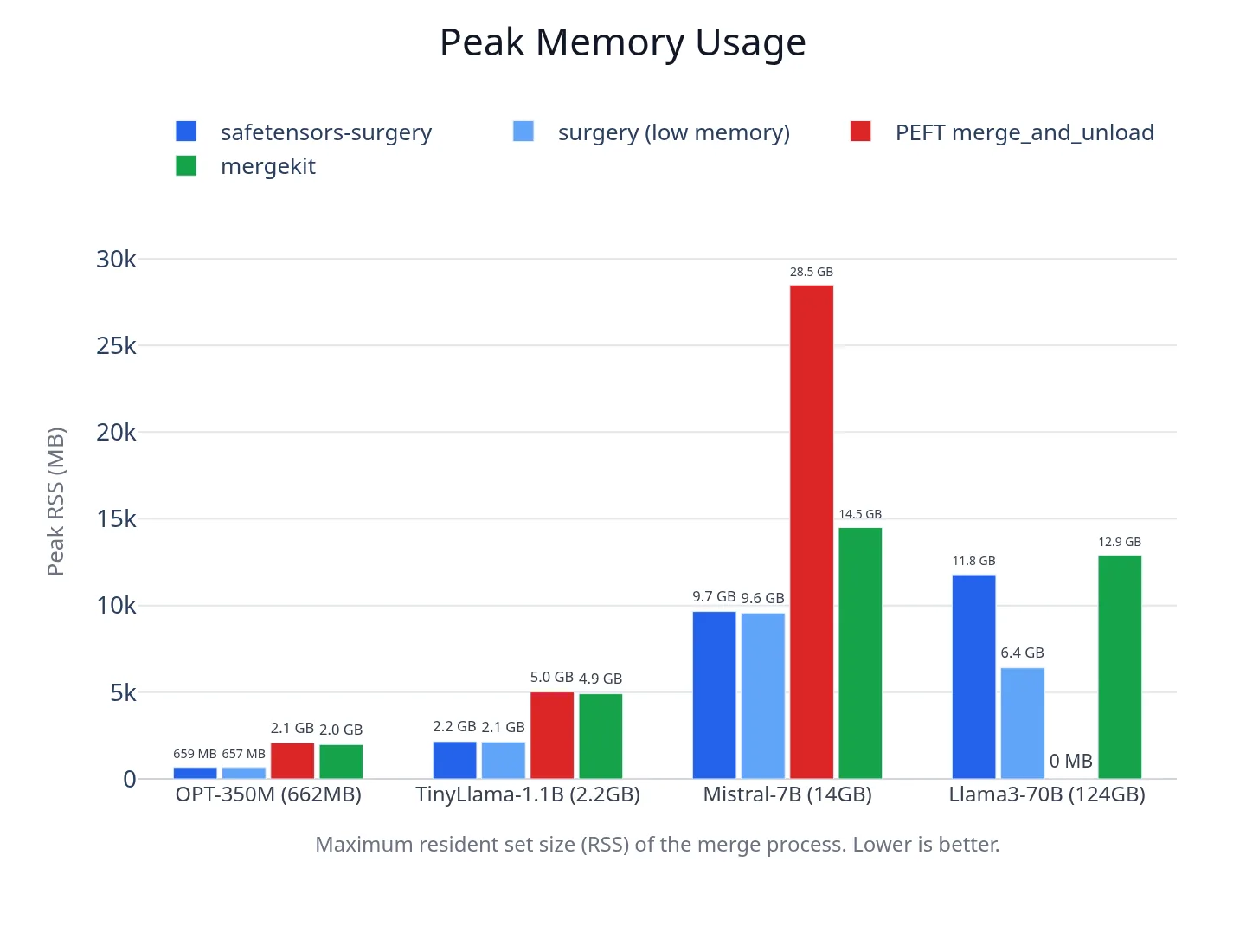
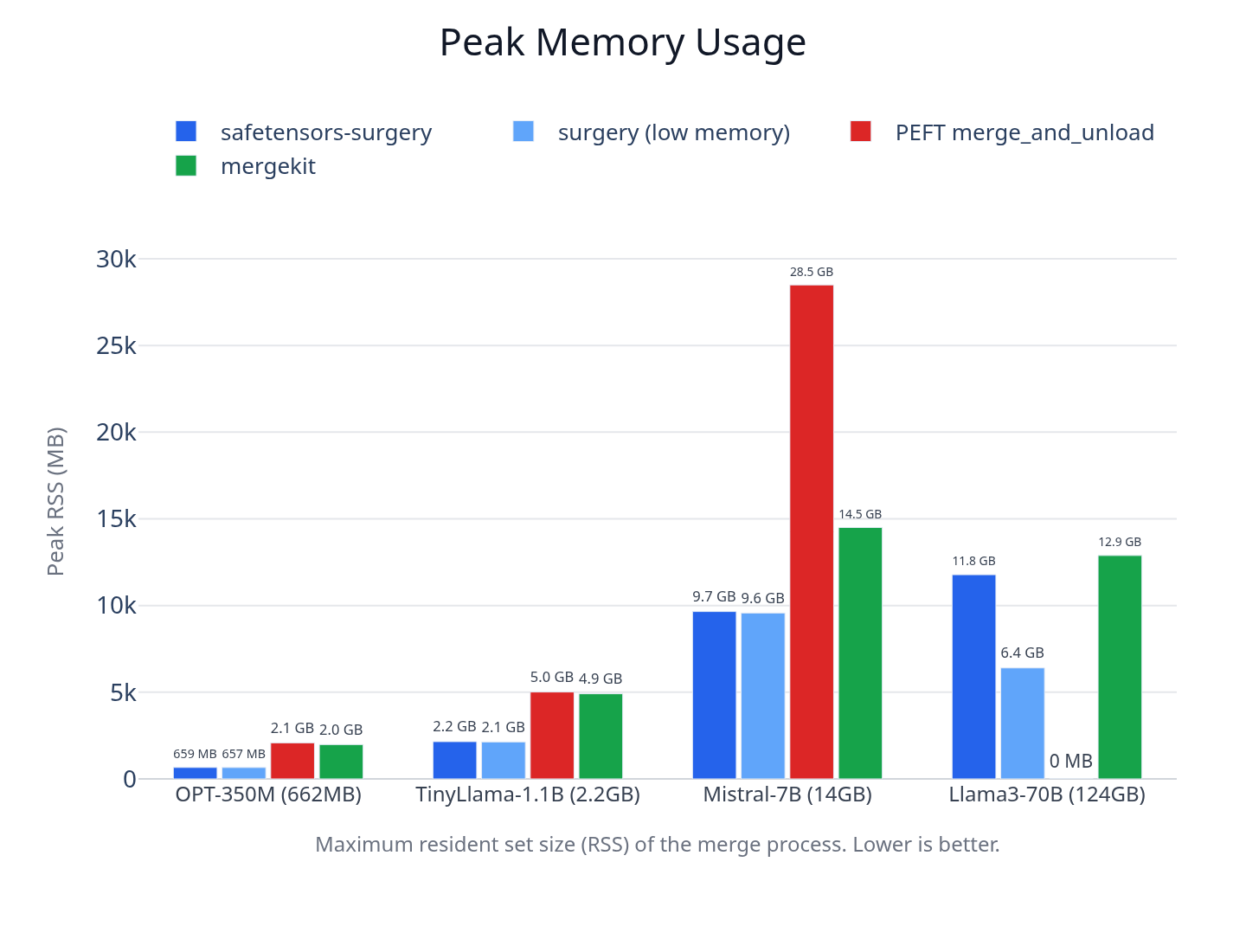
SafeTensors Surgery made it possible to merge large LoRA-adapted models with far lower memory requirements. In benchmarks run on a single 128GB workstation, Llama3-70B merged in 6.4GB of RAM with low-memory mode, compared with 12.9GB for mergekit on the same machine. PEFT could not complete the 70B merge on that workstation, because its standard merge path needed more memory than the 128GB available.
Modern AI models are distributed as large collections of numerical weights. Those weights are the learned parameters that determine how the model behaves. When a team fine-tunes a model for a specific use case, they often do not retrain or redistribute the entire model. Instead, they train a smaller add-on called a LoRA adapter, which changes the behavior of the base model without requiring a full copy of all the weights.
This workflow is useful during experimentation because one large base model can support many smaller adapters. A team might keep the base model fixed while using separate adapters for different customer workflows, product domains, or internal tasks. This keeps training and iteration lighter, because the adapter is much smaller than the model it modifies.
The challenge appears when the team wants to deploy the adapted model in an environment that expects one complete model artifact. At that point, the adapter has to be merged into the base model. The operation sounds straightforward, but it can require loading a very large model into memory, applying the adapter changes to the correct tensors, and writing a new model file that existing inference systems can load.
For large models, this becomes an infrastructure problem. A merge that works on a rented GPU server may fail on a local machine because the full model cannot fit into memory. Teams then have to keep expensive hardware running, move the merge into the cloud, or serve the model with the adapter applied at runtime, which can make deployment more complicated and inference slower.
The main problem was that existing LoRA merge workflows required too much memory for large models. PEFT's standard merge path loads the full model into memory. For Mistral-7B, this required about 28GB of RAM. For Llama3-70B, the requirement was well over 100GB, which is why the benchmark machine could not run it.
Mergekit reduced the memory burden, but memory use still scaled with model size. On Llama3-70B, mergekit used about 13GB of RAM. That was a major improvement over PEFT, though it still placed large merges outside the range of many consumer machines and lightweight development environments.
This mattered because adapter merging is often a deployment step rather than a training step. A team might train on rented hardware and then want to merge locally once training is complete. If the merge still requires cloud infrastructure, the team loses some of the operational advantage that LoRA adapters are supposed to provide.
The second problem was correctness. A merge tool needs to apply adapter deltas to the right base tensors, preserve non-adapted tensors exactly, and write a model artifact that behaves like the adapted model. If the merge changes tensors that should have been copied, uses lower-precision intermediate math, or mishandles sharded files, the output may load successfully while drifting away from the expected model.
SafeTensors Surgery was built to make LoRA merging a lower-memory checkpoint operation. The tool reads SafeTensors model files through memory-mapped I/O, which allows the operating system to stream weights from disk instead of loading the whole model into memory at once.
The merge process operates tensor by tensor. For each LoRA target tensor, the tool reads the base weight and the adapter matrices, applies the LoRA update, and writes the merged tensor to the output model. Non-LoRA tensors are byte-copied from the memory map to the output without allocation or conversion, which preserves passthrough tensors exactly.
The merge uses high-precision intermediate math. SafeTensors Surgery computes the LoRA update with f64 matrix multiplication accumulation and performs the final base-plus-delta addition in f64 before downcasting to the output dtype. This was done to preserve numerical accuracy that could be lost when the intermediate computation is performed in f32.
The tool also supports two merge paths. The default path materializes the full delta matrix in f64 for speed. The low-memory path tiles the matrix multiplication in fixed-size chunks, which bounds peak memory at the cost of slower runtime. This made the tool useful for cases where RAM was the limiting factor rather than wall-clock time.
SafeTensors Surgery supports single-file and sharded SafeTensors base models in fp16, bf16, or fp32. The base model must be unquantized. The output preserves the input layout, so a single-file model remains a single file, and a sharded model is written as shards with an index file.
The adapter input is PEFT-format LoRA. That means the adapter directory contains an adapter_config.json file and an adapter_model.safetensors file. This covers adapters trained with common workflows such as PEFT, Axolotl, Unsloth, and LLaMA-Factory, because those tools save through PEFT serialization.
The tool reads standard LoRA configuration fields such as the LoRA rank, alpha scaling factor, target modules, fan-in fan-out behavior, bias mode, and modules to save. It is focused on one adapter at a time, rather than multi-adapter merge methods.
SafeTensors Surgery was benchmarked against PEFT and mergekit across four model sizes. The benchmark measured peak resident memory, merge time, accuracy against a Python f64 reference merge, and whether non-LoRA tensors were preserved as bit-identical passthrough.
All runs used the same machine, an AMD Ryzen 9 9950X3D with 128GB of DDR5 memory and a 1TB NVMe drive. Each figure is the median of three runs.
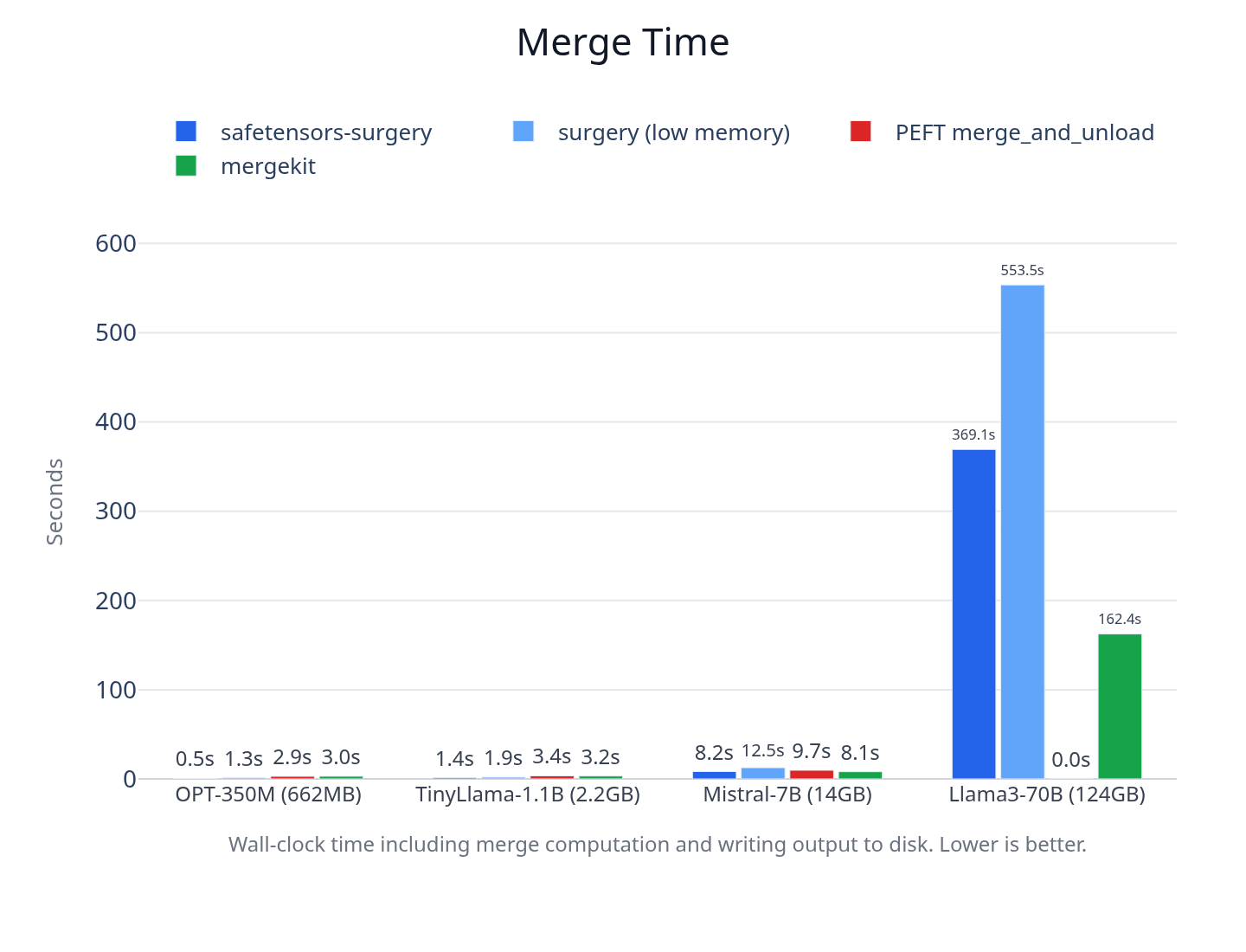
The table below pairs with the two figures and gives the exact numbers. The lowest peak memory in each model group is in bold.
| Model (base size) | Tool | Peak memory | Merge time |
|---|---|---|---|
| OPT-350M (662 MB) | Surgery | 659 MB | 0.5s |
| Surgery, low-memory | 657 MB | 1.3s | |
| PEFT | 2.1 GB | 2.9s | |
| mergekit | 2.0 GB | 3.0s | |
| TinyLlama-1.1B (2.2 GB) | Surgery | 2.2 GB | 1.4s |
| Surgery, low-memory | 2.1 GB | 1.9s | |
| PEFT | 5.0 GB | 3.4s | |
| mergekit | 4.9 GB | 3.2s | |
| Mistral-7B (14 GB) | Surgery | 9.7 GB | 8.2s |
| Surgery, low-memory | 9.6 GB | 12.5s | |
| PEFT | 28.5 GB | 9.7s | |
| mergekit | 14.5 GB | 8.1s | |
| Llama3-70B (124 GB) | Surgery | 11.8 GB | 369.1s |
| Surgery, low-memory | 6.4 GB | 553.5s | |
| PEFT | out of memory | did not finish | |
| mergekit | 12.9 GB | 162.4s |
Surgery used substantially less memory than PEFT and mergekit at every size. On Mistral-7B, Surgery used 9.7GB compared with 28.5GB for PEFT and 14.5GB for mergekit. On Llama3-70B, the low-memory mode used 6.4GB compared with 12.9GB for mergekit, while PEFT exceeded the memory available on the test machine and could not complete the merge.
The tradeoff was speed on very large models. At 70B scale, Surgery was slower than mergekit because the f64 matrix multiplication path performs more expensive computation on large projection matrices. The low-memory mode traded more time for lower RAM, which was useful when the goal was to complete the merge on a machine without server-class memory.
Correctness was measured separately from speed, by comparing each merge against a Python f64 reference and checking whether non-LoRA tensors were written byte for byte. Accuracy here means per-element ULP distance against that reference, where a ULP is the smallest representable gap between two floating point numbers.
Surgery stayed within 1 ULP of the f64 reference on every merge it completed, in both the default and low-memory paths. Passthrough was 100% across every completed merge, so the tensors the adapter does not touch were written identical to the base model. PEFT matched the reference on the models small enough to fit. mergekit matched on the three smaller models and diverged only at 70B, where some merged elements moved past the precision the output dtype can represent.
SafeTensors Surgery has a defined scope. The base model must be unquantized fp16, bf16, or fp32, so GPTQ, AWQ, and bitsandbytes 4-bit models are out of range. The tool merges a single adapter and does not implement multi-adapter methods such as TIES, DARE, or SLERP. It matches tensors by name and does not validate architecture, so pointing it at the wrong base model produces a valid but meaningless SafeTensors file with no warning. The output always keeps the base model's dtype, so a separate step is needed to convert a bf16 merge to fp16. As the benchmarks show, the f64 path also makes the tool slower than mergekit at 70B scale, where the projection matrices are large.
SafeTensors Surgery made LoRA adapter merging more accessible for teams working with large models. Instead of keeping a GPU server running, moving the merge into the cloud, or serving the adapter separately at runtime, teams could produce merged SafeTensors artifacts on machines with much lower memory limits.
The most important impact was control over the deployment artifact. The tool produced a single merged model file or sharded model directory that preserved the original dtype, metadata, and layout. Non-LoRA tensors remained bit-identical to the base model, and LoRA-merged tensors stayed within 1 ULP of a Python f64 reference merge.
For model teams, this created a cleaner path from experimentation to deployment. Adapters could remain lightweight during training and iteration, then be merged into the base model when the deployment environment required one artifact. SafeTensors Surgery turned that final merge from a high-memory infrastructure step into a repeatable local model operation.